Unlocking the Power of Big Data: A Comprehensive Guide to the MapReduce Algorithm
Related Articles: Unlocking the Power of Big Data: A Comprehensive Guide to the MapReduce Algorithm
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to Unlocking the Power of Big Data: A Comprehensive Guide to the MapReduce Algorithm. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Unlocking the Power of Big Data: A Comprehensive Guide to the MapReduce Algorithm
- 2 Introduction
- 3 Unlocking the Power of Big Data: A Comprehensive Guide to the MapReduce Algorithm
- 3.1 Understanding the MapReduce Paradigm
- 3.2 Benefits of the MapReduce Algorithm
- 3.3 Applications of MapReduce
- 3.4 Understanding the Ecosystem: Hadoop and Beyond
- 3.5 Addressing Common Concerns
- 3.6 Tips for Successful MapReduce Implementation
- 3.7 Conclusion
- 4 Closure
Unlocking the Power of Big Data: A Comprehensive Guide to the MapReduce Algorithm
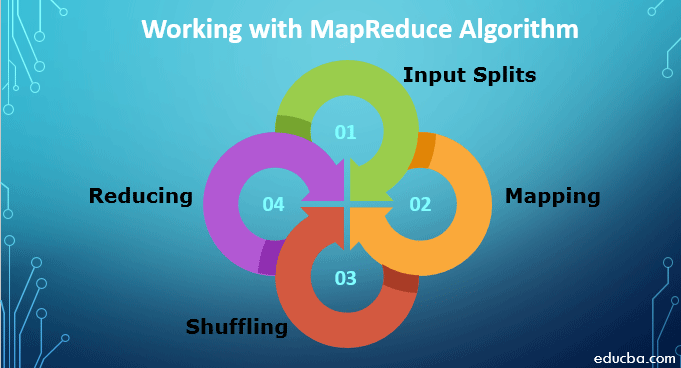
In the realm of Big Data, where datasets grow exponentially, traditional data processing methods often fall short. The sheer volume and complexity of information demand efficient and scalable solutions. Enter the MapReduce algorithm, a paradigm shift in data processing that has revolutionized how we handle massive datasets. This article will delve into the intricacies of MapReduce, exploring its core concepts, benefits, and applications, providing a comprehensive understanding of this transformative technology.
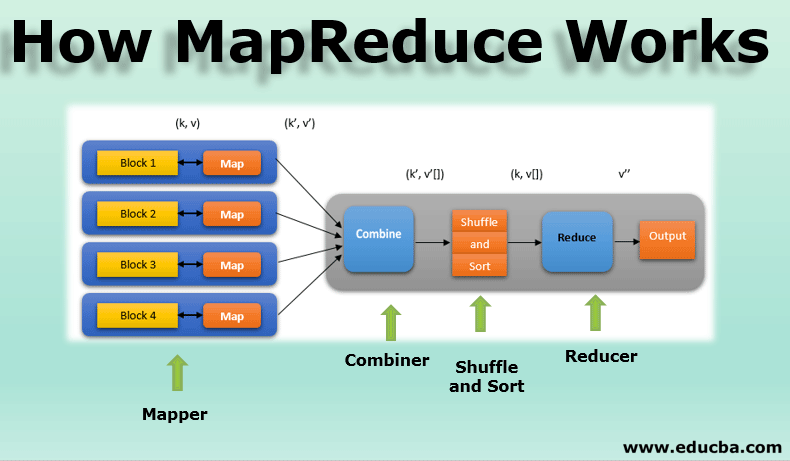
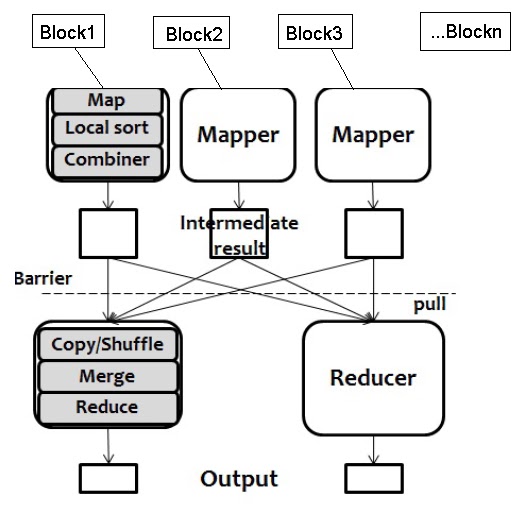
Understanding the MapReduce Paradigm
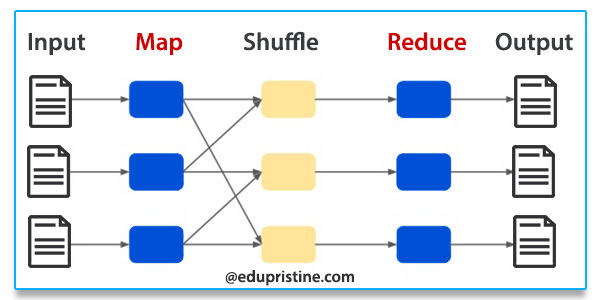
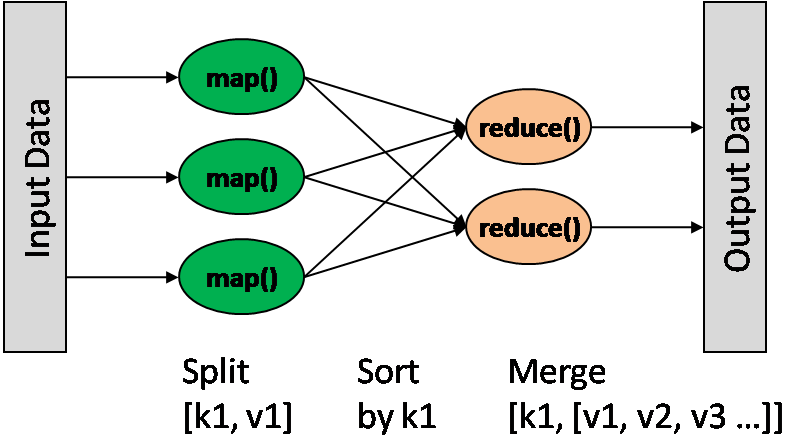
At its heart, MapReduce is a programming model that simplifies the processing of massive datasets by breaking down complex tasks into smaller, independent subtasks. It achieves this through two primary phases: Map and Reduce.
The Map Phase:
- Data Splitting: The initial dataset is divided into smaller, manageable chunks called "splits." Each split is processed independently, allowing for parallel execution.
- Key-Value Pair Generation: The Map function is applied to each split. This function transforms the raw data into key-value pairs, where the key represents a specific characteristic or category, and the value holds associated information.
The Reduce Phase:
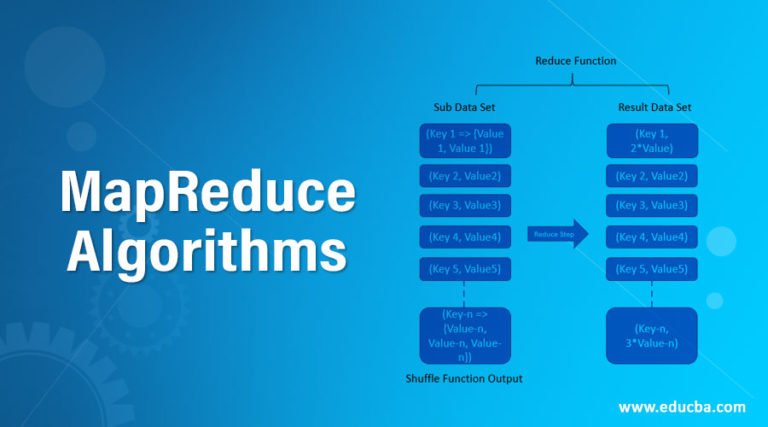
- Grouping: The Map phase outputs a set of key-value pairs. These pairs are grouped based on their keys, bringing together all values associated with a specific key.
- Aggregation: The Reduce function is applied to each group of key-value pairs. This function aggregates the values associated with each key, performing operations like summing, averaging, or counting.
Illustrative Example:
Imagine we want to count the occurrences of each word in a massive text file. Using MapReduce, we can:
- Map: Split the file into chunks, and for each chunk, generate key-value pairs where the key is a word and the value is 1.
- Reduce: Group all pairs with the same word, and sum the values (1s) to determine the word’s frequency.
Benefits of the MapReduce Algorithm
MapReduce offers several advantages that make it a powerful tool for Big Data processing:
- Scalability: MapReduce can handle massive datasets by distributing the workload across multiple nodes in a cluster. This parallelization significantly reduces processing time.
- Fault Tolerance: The distributed nature of MapReduce makes it resilient to failures. If a node fails, the task can be reassigned to another node without affecting the overall process.
- Simplicity: The MapReduce model is relatively simple to understand and implement, making it accessible to a broader range of developers.
- Flexibility: MapReduce can be adapted to handle various data processing tasks, from word counting to complex data analysis.
Applications of MapReduce
The MapReduce algorithm has found wide application across various domains, including:
- Web Search: Google’s search engine utilizes MapReduce to index and process massive amounts of web data.
- Social Media Analysis: MapReduce helps analyze user interactions, trends, and sentiment on social media platforms.
- E-commerce: Analyzing customer purchase patterns, recommending products, and identifying fraudulent activities are facilitated by MapReduce.
- Scientific Research: Researchers use MapReduce to process large datasets in fields like genomics, climate modeling, and astronomy.
Understanding the Ecosystem: Hadoop and Beyond
The MapReduce algorithm is often implemented using frameworks like Hadoop. Hadoop is an open-source software framework that provides a platform for distributed storage and processing of large datasets. It consists of two main components:
- Hadoop Distributed File System (HDFS): A distributed file system that stores data across multiple nodes, ensuring high availability and scalability.
- Yet Another Resource Negotiator (YARN): A resource manager that allocates resources to applications running on the Hadoop cluster.
Beyond Hadoop, other frameworks like Spark and Apache Flink have emerged, offering more advanced features and performance optimizations. These frameworks build upon the core concepts of MapReduce but provide enhanced functionality and efficiency.
Addressing Common Concerns
While MapReduce has proven its value, it is important to acknowledge potential limitations and address common concerns:
1. Data Locality: In some cases, data might be physically located far from the processing nodes, leading to increased network latency and reduced performance.
2. Data Skew: If the data distribution is uneven, certain nodes might be overloaded with data, leading to imbalances and performance bottlenecks.
3. Complex Data Models: Handling complex data models and nested structures within the MapReduce framework can be challenging.
4. Debugging: Debugging MapReduce applications can be complex due to the distributed nature of the processing.
Tips for Successful MapReduce Implementation
To maximize the effectiveness of MapReduce, consider these tips:
- Optimize Data Input: Ensure data is formatted and pre-processed efficiently to minimize processing overhead.
- Partition Data Strategically: Partition data based on relevant keys to ensure even distribution and optimize processing.
- Choose the Right Framework: Select a framework like Hadoop, Spark, or Flink based on your specific needs and performance requirements.
- Monitor and Analyze Performance: Regularly monitor the performance of your MapReduce applications to identify bottlenecks and areas for optimization.
Conclusion
The MapReduce algorithm has revolutionized Big Data processing by enabling efficient and scalable handling of massive datasets. Its simplicity, scalability, and fault tolerance make it a powerful tool for various applications. While challenges like data locality and skew exist, the ongoing development of frameworks like Hadoop, Spark, and Flink address these limitations and enhance the capabilities of MapReduce. As Big Data continues to grow, the MapReduce paradigm will remain a cornerstone of data processing, empowering us to unlock the potential of vast information repositories and drive innovation across diverse fields.



Closure
Thus, we hope this article has provided valuable insights into Unlocking the Power of Big Data: A Comprehensive Guide to the MapReduce Algorithm. We appreciate your attention to our article. See you in our next article!