Demystifying Hadoop MapReduce: A Comprehensive Guide with Practical Examples
Related Articles: Demystifying Hadoop MapReduce: A Comprehensive Guide with Practical Examples
Introduction
In this auspicious occasion, we are delighted to delve into the intriguing topic related to Demystifying Hadoop MapReduce: A Comprehensive Guide with Practical Examples. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Demystifying Hadoop MapReduce: A Comprehensive Guide with Practical Examples
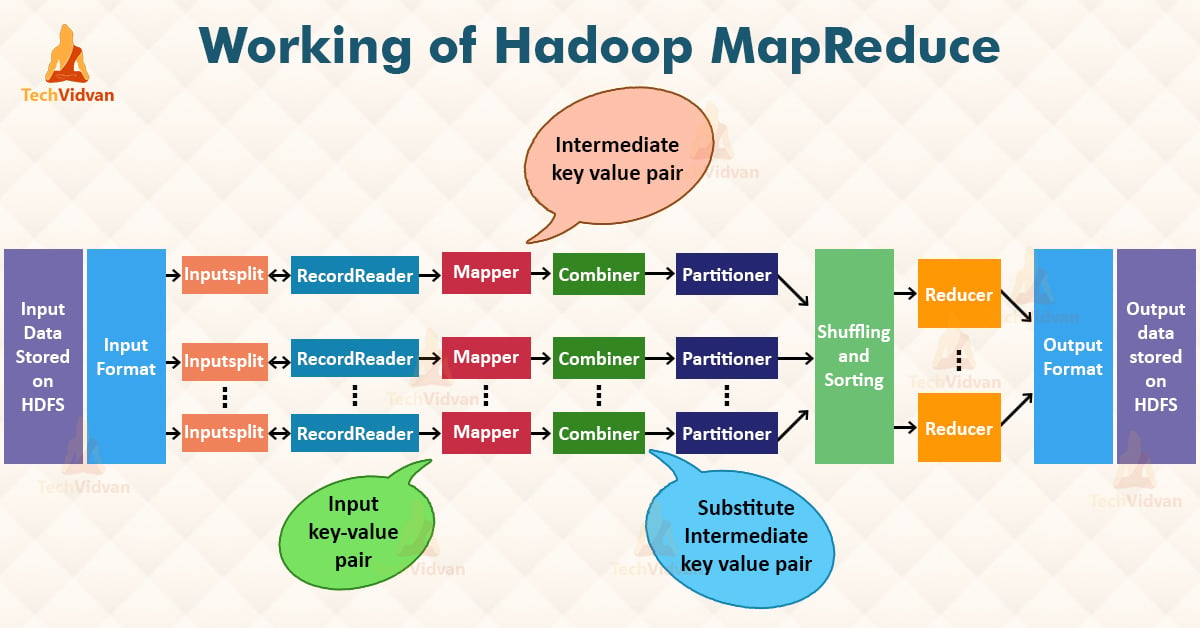
Hadoop MapReduce, a cornerstone of big data processing, empowers organizations to handle massive datasets efficiently and effectively. This distributed computing framework, renowned for its scalability and fault tolerance, has become a vital tool for extracting valuable insights from data that would otherwise be overwhelming to process. This guide delves into the fundamentals of Hadoop MapReduce, illustrating its workings through practical examples and highlighting its significance in the modern data landscape.
Understanding the Core Concepts
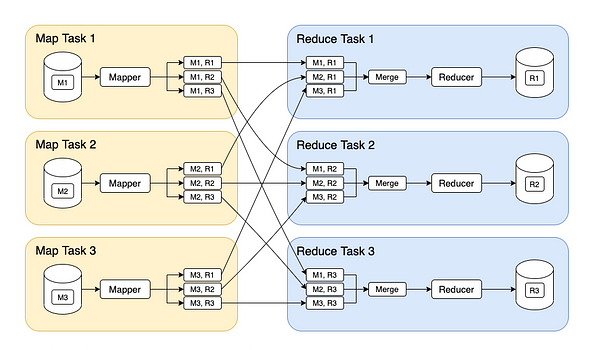
Hadoop MapReduce, at its heart, is a programming model designed for parallel processing of large datasets across a cluster of computers. It operates in two distinct phases:
- Map Phase: This phase involves breaking down the input data into key-value pairs and applying a user-defined map function to each pair. This function transforms the data into a new set of key-value pairs.
- Reduce Phase: The map phase outputs are then grouped by keys, and a user-defined reduce function is applied to each group. This function combines the values associated with each key, producing a final output.
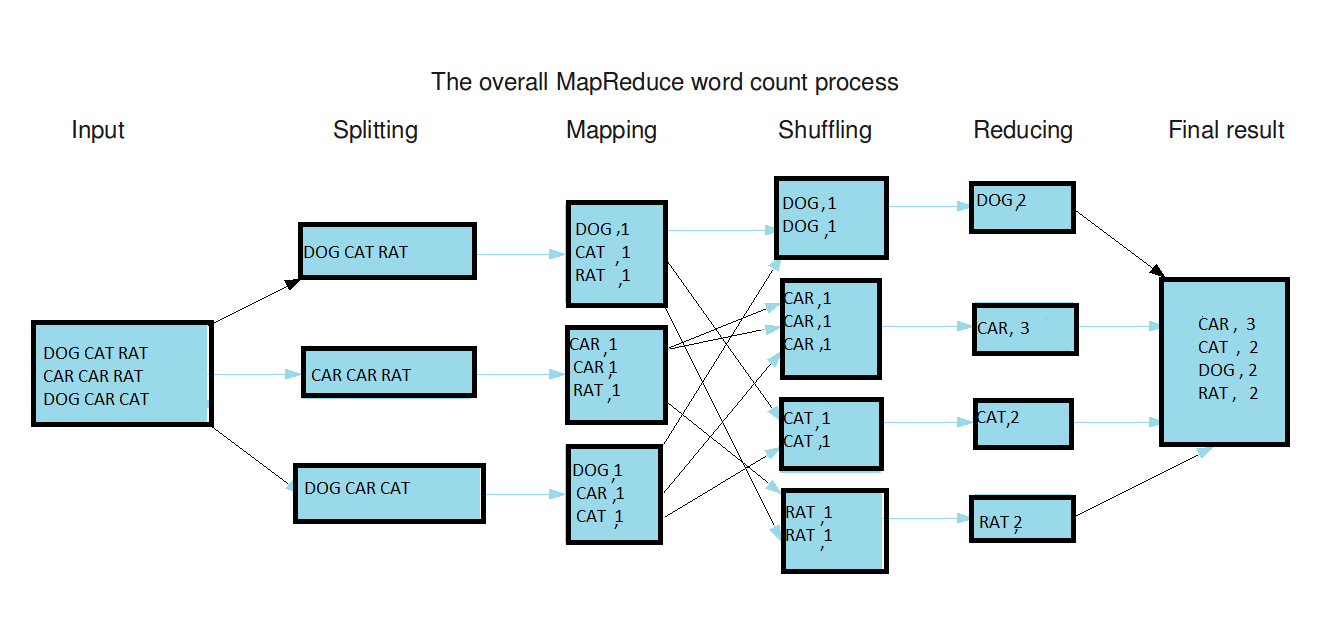
A Practical Example: Word Count
To understand the mechanics of Hadoop MapReduce, let’s consider a classic example: counting the frequency of words in a large text file.
1. Input Data:
Imagine a text file containing the following sentence: "The quick brown fox jumps over the lazy dog."
2. Map Phase:
- Input: Each word in the sentence becomes a key-value pair. For instance, "The" becomes ("The", 1).
- Map Function: The map function simply counts the occurrence of each word. So, "The" becomes ("The", 1), "quick" becomes ("quick", 1), and so on.
3. Shuffle and Sort:
The map phase outputs are then shuffled and sorted based on the keys (words). This ensures that all occurrences of a specific word are grouped together.
4. Reduce Phase:
- Input: The shuffled and sorted data is fed into the reduce phase. For example, "The" will be associated with a list of 1s, representing its occurrences.
- Reduce Function: The reduce function sums up the values for each key. In this case, the reduce function for "The" would add the two 1s, resulting in ("The", 2).
5. Output:
The final output of the reduce phase is a list of words and their corresponding counts, providing a word frequency analysis of the input text.
Beyond Word Count: Real-World Applications
While the word count example provides a basic understanding of Hadoop MapReduce, its applications extend far beyond simple word counting. This framework is employed across diverse domains, including:
- Web Analytics: Analyzing user behavior, website traffic patterns, and clickstream data to optimize website performance and user experience.
- Social Media Analysis: Extracting insights from social media data, such as sentiment analysis, trend identification, and community detection.
- Scientific Research: Processing vast amounts of data generated by scientific experiments, simulations, and observations.
- Financial Modeling: Analyzing financial data to identify trends, predict market behavior, and manage risk.
- Fraud Detection: Identifying patterns in transactional data to detect fraudulent activities.
Benefits of Hadoop MapReduce
The adoption of Hadoop MapReduce stems from its inherent advantages:
- Scalability: The framework can handle massive datasets by distributing processing across multiple nodes, enabling efficient processing of data that exceeds the capacity of a single machine.
- Fault Tolerance: If a node fails during processing, the framework automatically redistributes the workload to other available nodes, ensuring uninterrupted operation and data integrity.
- Cost-Effectiveness: Hadoop MapReduce utilizes commodity hardware, making it an economical solution for big data processing compared to expensive specialized systems.
- Flexibility: The framework allows for customization of map and reduce functions, enabling developers to tailor processing logic to specific business requirements.
Frequently Asked Questions (FAQs)
Q1: What is the difference between Hadoop and MapReduce?
A: Hadoop is a distributed file system and processing framework, while MapReduce is a programming model within Hadoop for parallel processing of data. Hadoop provides the infrastructure for storing and processing data, while MapReduce defines the logic for how that data is processed.
Q2: What are the limitations of Hadoop MapReduce?
A: While powerful, Hadoop MapReduce has some limitations:
- Data Locality: Data is often physically distributed across multiple nodes, which can lead to network overhead during processing.
- Performance Overhead: The framework’s overhead for data shuffling and sorting can impact performance, especially for complex processing tasks.
- Limited Flexibility: The framework’s rigid structure can sometimes restrict developers from implementing highly customized processing logic.
Q3: What are the alternatives to Hadoop MapReduce?
A: Several alternatives to Hadoop MapReduce have emerged, including:
- Spark: A faster and more versatile framework that supports a wider range of processing paradigms.
- Flink: A real-time stream processing framework capable of handling continuous data streams.
- Hive: A data warehouse system that provides a SQL-like interface for querying data stored in Hadoop.
Tips for Implementing Hadoop MapReduce
- Optimize Data Locality: Ensure data is stored close to the processing nodes to minimize network overhead.
- Choose Appropriate Data Formats: Select data formats that are efficient for storage and processing, such as Avro or Parquet.
- Tune MapReduce Parameters: Adjust parameters like the number of mappers and reducers to optimize performance for specific workloads.
- Leverage Hadoop Ecosystem Tools: Utilize tools like Hive, Pig, and Oozie for simplifying data manipulation and workflow management.
Conclusion
Hadoop MapReduce, despite its limitations, remains a powerful tool for processing large datasets. Its inherent scalability, fault tolerance, and cost-effectiveness make it a valuable asset for organizations dealing with big data challenges. Understanding the fundamentals of this framework, its practical applications, and its benefits is crucial for leveraging its capabilities in the modern data-driven world. As data continues to grow exponentially, Hadoop MapReduce will likely continue to play a vital role in unlocking the potential of this data and driving informed decision-making.






Closure
Thus, we hope this article has provided valuable insights into Demystifying Hadoop MapReduce: A Comprehensive Guide with Practical Examples. We hope you find this article informative and beneficial. See you in our next article!